Modelli a strati
Il modello a strati è una comoda rappresentazione dei sistemi di rete che permette concettualmente di separare le diverse funzionalità in strati di protocolli, permettendo così di studiare più facilmente i protocolli di rete.
L'idea della stratificazione è fondamentale per poter disegnare l'architettura software strutturata in livelli, ognuno dei quali con i suoi vari protocolli, tratta una parte specifica dei problemi di trasmissione.
Il concetto di stratificazione poggia su un principio basilare il quale, in sostanza, afferma che lo strato ennesimo alla stazione destinazione deve ricevere un pacchetto identico a quello che è uscito dal medesimo livello alla stazione sorgente. I due principali esempi di modelli stratificati sono rappresentati dal Open System Interconnection (OSI) dell'ISO e dal TCP/IP. Si può pensare al software di una macchina come costituito da tanti strati ognuno dei quali svolge una funzionalità specifica propria.
Inoltre è importante sottolineare che uno strato comunica soltanto con uno strato immediatamente superiore od inferiore, tramite delle interfacce standard, mentre all'interno dello strato la comunicazione può avvenire in un qualunque modo; per poter comunicare da uno strato n ad uno strato n-2 (n+2) bisogna necessariamente passare attraverso lo strato intermedio n-1 (n+1).
Concettualmente, mandare un messaggio da un programma su una macchina ad un programma su un'altra, significa trasferire tale messaggio giù attraverso tutti i vari strati fino al livello di rete e, tramite l'hardware, raggiungere l'altra macchina, risalire gli strati software in successione fino al livello di applicazione dell'utente destinazione.
In particolare il software TCP/IP è organizzato concettualmente in quattro livelli più un quinto costituito dal supporto fisico vero e proprio. La figura mostra i quattro livelli:
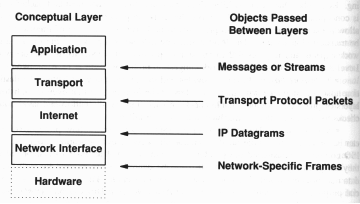
Application Layer : A livello più alto, l'utente invoca i programmi applicativi che permettono di accedere ai servizi disponibili attraverso Internet; tale livello riguarda tutte le possibili opzioni, chiamate, necessità dei vari programmi. In pratica gestisce l'interattività tra l'utente e la macchina.
Un programma applicativo interagisce con uno dei protocolli di livello trasporto per inviare o ricevere dati e li passa al livello trasporto nella forma richiesta.
Tranport Layer : Lo scopo primario del livello trasporto è consentire la connessione in rete fra due utenti ovvero permettere la comunicazione tra un livello applicativo ed un altro; una comunicazione di questo tipo è spesso detta "end-to-end".
Il software di tale livello divide il flusso di dati in pacchetti (di solito di circa 500 byte) che vengono passati insieme all'indirizzo di destinazione allo strato sottostante. Il livello di trasporto deve accettare dati da molti utenti contemporaneamente e, viceversa, deve smistare i pacchetti che gli arrivano dal sotto ai vari specifici programmi; deve quindi usare dei codici appositi per indicare le cosiddette porte.
Le routine di trasporto pacchetti aggiungono ad ogni di pacchetto, alcuni bit in più atti a codificare, fra l'altro, i programmi sorgente e destinazione.
Il livello di trasporto può regolare il flusso di informazioni e può, nel caso del TCP (a differenza dell'UDP), fornire un trasporto affidabile assicurando che i dati giungano a destinazione senza errori ed in sequenza mediante un meccanismo di acknowledgement e ritrasmissione.
Internet Layer (IP) : Questo livello gestisce la comunicazione tra una macchina ed un'altra; accetta una richiesta di inoltro di un pacchetto da un livello di trasporto insieme all'identificazione della macchina alla quale il pacchetto deve essere inviato.
È il livello più caratteristico della internet, detto appunto IP (internet protocol) che crea il datagramma di base della rete, sostanzialmente, riceve e trasferisce senza garanzie i pacchetti, che gli arrivano da sopra, verso la macchina destinataria.
Esso accetta i pacchetti TCP, li spezzetta se necessario e li incapsula nei datagramma di base IP, riempie gli header necessari ed usa l'algoritmo di rouiting per decidere a chi deve mandare questo pacchetto, in particolare se si tratta di un caso di routing diretto o indiretto.
Il livello Internet gestisce anche i datagrammi in ingresso, verifica la loro validità ed usa l'algoritmo di routing per decidere se il datagramma deve essere inoltrato o processato localmente; in quest'ultimo caso il software elimina l' header del datagramma e sceglie quale protocollo di trasporto gestirà il pacchetto.
In tale fase non solo si svolge la funzione di instradamento, ma si verifica anche la validità dei pacchetti ricevuti.
Inoltre questo livello gestisce integralmente i messaggi ICMP in ingresso ed uscita.
Network Interface Layer : Il quarto ed ultimo strato è costituito da una interfaccia di rete che accetta il datagramma IP e lo trasmette, previo incapsularlo in appositi frame, sull'hardware di rete (il cavo) tramite, ad esempio, un transceiver.
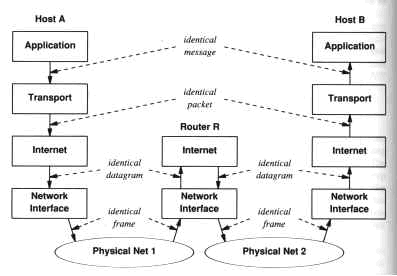
Da notare che se necessario il pacchetto può attraversare altre macchine intermedie (router) prima di giungere a destinazione, ma in queste penetra solo i due strati più bassi dell'interfaccia di rete e del datagramma base IP.
Uno dei vantaggi più significativi di questa separazione concettuale è che diventa possibile, entro certi termini, sostituire una parte senza disturbare necessariamente le altre, cosicché ricerca e sviluppo possono procedere concorrentemente su ognuno dei tre livelli.
Confronto tra TCP/IP e ISO/OSI (ex: X.25)
La prima differenza tra i due modelli sta nel numero di strati, in particolare, sette per l'OSI e cinque per internet. Esistono due sottili ma importanti differenze fra lo schema a strati dell'internet e quello del X.25 che è il più famoso protocollo aderente alla normative ISO. La prima riguarda l'affidabilità del servizio di trasporto dati e la seconda la localizzazione dell'autorità e controllo.
Nel modello X.25 il software del protocollo verifica l'integrità dei dati ad ognuno dei primi quattro livelli (escluso ovviamente il livello fisico di rete). In particolare, i livelli due e tre, cioè del link e del network, includono oltre al checksum un meccanismo di "timeout and retransmission", mentre il livello quattro del transport realizza l'affidabilità finale detta "end-to-end". Questo crea dei problemi, poiché ogni operazione di checksum mette in rete un ack ed ogni volta che si eccede il timeout viene duplicato un pacchetto, tutte queste operazioni sono ripetute ad ogni nodo attraversato anche se di passaggio (nel senso che vi si penetra solo al livello minimo, cioè di link).
Al contrario, nell'internet l'affidabilità è solamente un problema "end-to-end", infatti il livello di trasporto, e quindi la destinazione e la sorgente, è l'unico a gestire le ritrasmissioni e gli ack; i nodi di passaggio sono pressoché trasparenti anche se in effetti, hanno la capacità di buttar via i pacchetti se sono corrotti o se i buffer sono pieni.
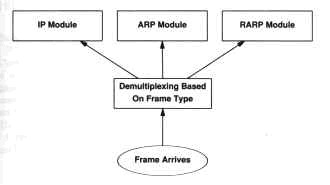
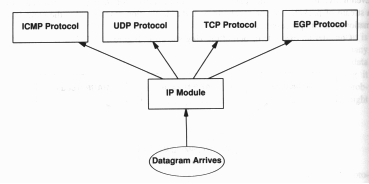
Protocolli: Multiplexing e Demultiplexing
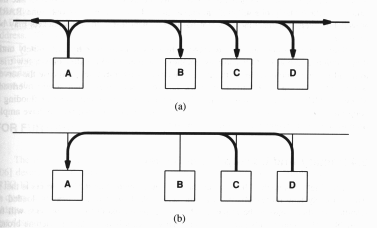
In generale, il multiplexing ed il demultiplexing sono tecniche largamente usate per sfruttare meglio il mezzo trasmissivo. Ad esempio, il TDMA permette di trasmettere più canali multiplexati, sfruttando un unico supporto fisico, salvo demultiplexare i canali stessi a destinazione.
In particolare, una rete non usa un singolo protocollo per adempiere ai molteplici compiti della trasmissione, ma, piuttosto, si basa su quella che potremmo definire una famiglia di protocolli. In pratica nei sistemi di comunicazione si usa una tecnica di multiplexing e demultiplexing per distinguere fra i vari protocolli ad uno stesso livello gerarchico.
Quando si spedisce un messaggio, il computer sorgente include dei bit in più per codificare il tipo di messaggio, il processo che lo ha generato ed il protocollo usato. Alla destinazione finale, la macchina demultiplexa i codici e guida così l'informazione verso la giusta procedura.